Building an Enterprise SSO Service From Scratch — No Cloud KMS, No Shortcuts
may 19, 2026
|14 min read
Ever integrated with Auth0, Firebase Auth, or Cognito and thought — "I could build this better for my specific use case"?
Or worse — paid $0.05 per MAU for a managed auth service that still doesn't support the exact token rotation strategy, role model, or domain isolation your platform needs?
If you've worked on multi-tenant platforms, startup ecosystems, or any system where authentication is the backbone — you know the pain.
Managed auth services give you speed. But they take away control.
You can't customize the JWT claims structure. You can't implement family-based refresh token reuse detection. You can't enforce domain-level isolation at the middleware layer. You can't decide that your audit logs should be immutable at the database trigger level.
And eventually, one of two things happens:
- You hack around the managed service's limitations with workarounds that become tech debt.
- Or you accept the constraints and ship a product that doesn't match your security model.
Both are compromises.
This is why I built the SSO Auth Service — a complete, enterprise-grade single sign-on platform. From scratch. No Auth0. No Firebase. No cloud KMS. Every cryptographic decision intentional. Every security control auditable.
In this deep dive, I'll walk through:
- Why I chose to build authentication infrastructure from zero.
- The cryptographic foundation (RSA-4096, Argon2id, Fernet).
- How family-based refresh token rotation catches stolen tokens.
- A three-role RBAC model with Layer 2 domain isolation.
- Immutable audit logging enforced by database triggers.
- The full architecture: FastAPI + PostgreSQL + Redis.
If you're interested in how production authentication systems actually work under the hood — not the marketing page version — read on.
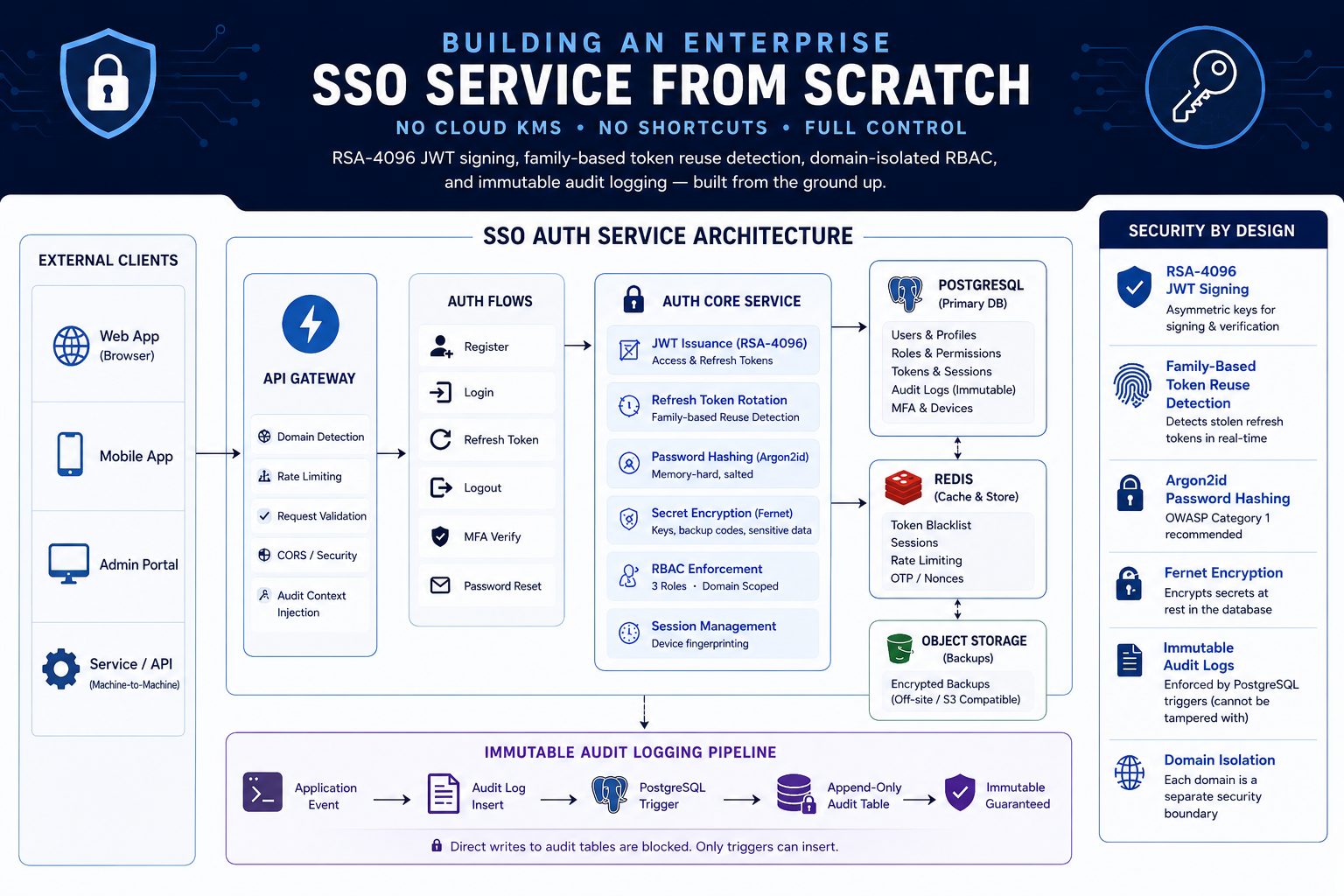
Why Build Your Own SSO?
The standard advice is "never roll your own auth." And for most applications, that's correct. But there's a difference between rolling your own cryptography and building your own authentication service using battle-tested cryptographic primitives.
I'm not inventing new hashing algorithms. I'm using:
- Argon2id — OWASP Category 1 recommended password hashing.
- RSA-4096 — Industry-standard asymmetric signing.
- Fernet (AES-128-CBC + HMAC-SHA256) — Authenticated encryption for secrets.
- SHA-256 — One-way hashing for fingerprints and backup codes.
What I am building is the orchestration layer — how these primitives compose into flows that match my platform's exact security requirements.
The platform has three distinct user domains (builders, founders, VCs) that must be cryptographically isolated from each other. No managed auth service offers domain-level middleware isolation out of the box. I needed it. So I built it.
The Cryptographic Foundation
Every security decision in this system traces back to a specific threat model. Here's the stack:
RSA-4096 JWT Signing — No Symmetric Key Exposure
# JWT signed with RSA-4096 private key
# Downstream services verify with public key via JWKS endpoint
# Private key NEVER leaves the auth service
Algorithm: RS256 (RSASSA-PKCS1-v1.5 + SHA-256)
Key Size: 4096 bits (OWASP recommendation, not 2048)
Storage: Environment variable (PEM format)
Public Key: Published at /.well-known/jwks.jsonWhy RSA-4096 instead of HS256? With symmetric signing, every service that verifies tokens must hold the secret. One compromised microservice leaks the signing key. With asymmetric signing, downstream apps only need the public key — they can verify but never forge tokens.
Argon2id Password Hashing — 1.5 Seconds Per Hash
# Argon2id parameters (OWASP-recommended)
Memory: 65536 KB (~64 MB)
Iterations: 3
Parallelism: 2 threads
Salt: 16 bytes (random per password)
Duration: ~1.5 seconds per hash
# This makes brute-force attacks computationally infeasible
# Even with GPU clusters, the memory-hard requirement kills parallelismArgon2id is memory-hard. Unlike bcrypt, it can't be efficiently parallelized on GPUs or ASICs. The 64 MB memory requirement per hash means an attacker needs 64 GB of RAM just to run 1,000 parallel attempts.
HIBP Integration via k-Anonymity
Before any password is accepted, it's checked against the Have I Been Pwned database — without ever sending the password:
1. SHA-1(password) → "5BAA61E4C9B93F3F0682250B6CF8331B7EE68FD8"
2. Send prefix "5BAA6" to HIBP API
3. Receive ~500 hash suffixes that match the prefix
4. Locally check if full hash exists in response
5. If found → password rejected ("This password appeared in a data breach")
Result: Password NEVER transmitted. HIBP sees only a 5-char prefix
shared by thousands of different passwords.
This is privacy-preserving breach detection. The user's password never leaves the server.
Family-Based Refresh Token Reuse Detection
This is the feature I'm most proud of. It's the difference between "we have refresh tokens" and "we detect token theft in real-time."
The Problem
Refresh tokens are long-lived (30 days). If an attacker steals one, they can silently generate new access tokens indefinitely — unless you detect the theft.
The Solution: Token Families
Every refresh token belongs to a family (identified by family_id). When a token is rotated, the old one is marked as used:
Refresh Token Family (family_id: ABC)
├─ Token 1 (created at login, used=false)
│ └─ rotated → Token 2
├─ Token 2 (used=true, Token 1 marked used)
│ └─ rotated → Token 3
├─ Token 3 (used=true, Token 2 marked used)
│ └─ current active token
The Detection
If an attacker replays Token 1 (which they stole earlier):
1. Token 1 arrives at /auth/refresh
2. System checks: Token 1 is marked "used" ← already rotated
3. Multiple tokens in family ABC are marked used
4. REUSE DETECTED → entire family revoked
5. Session terminated immediately
6. Legitimate user's next refresh fails → forced re-login
7. AuditLog: "REFRESH_TOKEN_REUSE_DETECTED" (immutable)
The attacker gets nothing. The legitimate user is forced to re-authenticate (inconvenient but safe). The security team has an immutable audit trail of the compromise attempt.
Why This Matters
Most auth systems just rotate tokens. They don't detect when an old token resurfaces. Family-based detection turns a passive rotation mechanism into an active intrusion detection system.
Device Fingerprinting & Suspicious Login Detection
When a user logs in, the system generates a device fingerprint:
device_fingerprint = SHA-256(User-Agent + IP)This fingerprint is compared against the user's known devices in sso_user_device. If it's a new fingerprint:
# New device detected
suspicious_login = True
# Flag in session metadata
# Risk service evaluates:
# - Is this a new country/region?
# - Is this a known VPN/proxy IP?
# - Was the last login from a different continent 5 minutes ago?
# If high risk → require MFA re-verificationThis catches account takeovers even when the attacker has valid credentials. A login from a new device in a new location triggers additional verification — without blocking legitimate users who simply switched browsers.
MFA: TOTP with Backup Codes
Multi-factor authentication follows RFC 6238 (TOTP) with a complete recovery flow:
Enrollment:
1. POST /mfa/enroll API → generates TOTP secret
2. Secret encrypted with Fernet, stored in DB
3. QR code (otpauth:// URI) returned as base64 PNG
4. User scans with authenticator app
5. POST /mfa/verify API → verifies first code
6. 8 backup codes generated (8-char hex, SHA-256 hashed)
7. Backup codes displayed ONCE — user must save them
Login with MFA:
1. POST /login API → returns mfa_challenge token (not access token)
2. POST /mfa/verify → validates TOTP code (±30s window)
3. If valid → access_token + refresh cookie issued
4. If invalid → attempt counted, rate limited
Recovery:
- Backup code can replace TOTP code (single-use)
- Each code SHA-256 hashed — no plaintext in DB
- After all 8 used → user must contact support
Tech Stack
| Layer | Technology | Why |
|---|---|---|
| Framework | FastAPI | Async-native, auto-generated OpenAPI docs, Pydantic validation |
| ORM | SQLAlchemy Async | Type-safe queries, async connection pooling |
| Database | PostgreSQL 15 | ACID transactions, triggers, JSON columns |
| Cache | Redis 7 | Sub-millisecond session lookups, atomic rate limiting |
| Hashing | Argon2id | Memory-hard, GPU-resistant, OWASP recommended |
| Signing | RSA-4096 | Asymmetric — verify without the signing key |
| Encryption | Fernet | Authenticated encryption for TOTP secrets |
| Container | Docker | Multi-stage build, ~300 MB production image |
| Testing | pytest | 100+ integration tests, 88%+ coverage |
Downstream Integration
Instead of routing every single HTTP request back to the central authentication service to verify credentials—which introduces significant latency, creates a single point of failure, and places unnecessary load on the core database—downstream services verify tokens locally using asymmetric signature verification.
How Local Verification Works
- JWKS Fetching & Caching: The SSO auth service exposes a public JSON Web Key Set (JWKS) endpoint at
/.well-known/jwks.json. This endpoint contains only the public keys used to sign the JSON Web Tokens (JWTs). Downstream microservices query this endpoint once, retrieve the public keys, and cache them in memory. - Signature Verification: When a request arrives at a downstream service with a JWT in the
Authorizationheader, the service decodes the token's header to identify the signing key (using thekidor Key ID claim). It then uses the cached public key to verify that the cryptographic signature is valid. If the signature matches, the service can trust the token's contents implicitly. - Claims Validation: Once the signature is verified, the downstream service checks the standard JWT claims locally:
exp(Expiration Time): Ensuring the token is still active and has not expired.iss(Issuer): Confirming the token was actually issued by the trusted SSO service.aud(Audience): Verifying the token was intended for the current service.- Custom Claims: Extracting the user's ID, roles, and permissions to make immediate access-control decisions.
This local validation workflow ensures zero network overhead for downstream requests. The central auth service is only contacted when users log in, request a new access token via a refresh token, or explicitly log out. It works seamlessly and efficiently across the entire platform.
Security Controls Summary
| Control | Implementation |
|---|---|
| Password Hashing | Argon2id (64 MB, 3 iterations, ~1.5s) |
| JWT Signing | RSA-4096, RS256 |
| Secret Encryption | Fernet (AES-128-CBC + HMAC-SHA256) |
| Breach Detection | HIBP k-anonymity (password never transmitted) |
| Token Theft Detection | Family-based refresh token reuse detection |
| Domain Isolation | Layer 2 middleware (JWT role → URL domain) |
| Rate Limiting | Redis sliding-window counters per endpoint |
| Audit Immutability | PostgreSQL triggers (no UPDATE/DELETE) |
| Device Tracking | SHA-256 fingerprinting + suspicious login flags |
| MFA | TOTP RFC 6238 + 8 single-use backup codes |
| Cookie Security | HttpOnly, Secure, SameSite=Strict, Path-scoped |
| CORS | Exact origin matching (no wildcards) |
| SQL Injection | Parameterized queries via ORM (zero raw SQL) |
| Timing Attacks | Constant-time Argon2id comparison |
What I Learned Building This
-
Authentication is an iceberg. Login/signup is 10% of the work. Token rotation, reuse detection, device tracking, rate limiting, and audit logging are the other 90%.
-
Defense in depth isn't optional. Domain isolation at the middleware layer AND route guards. Immutable audit logs at the trigger level AND application-level logging. Every critical control has a backup.
-
No cloud KMS is a valid choice. For small-to-medium deployments, local key management eliminates network latency, vendor lock-in, and external dependencies. The tradeoff is manual key rotation — acceptable for a platform that isn't serving 100M users.
-
Refresh token rotation without reuse detection is security theater. Rotating tokens is meaningless if you can't detect when an old token resurfaces. Family-based detection turns rotation into an active defense mechanism.
-
The "no admin API" pattern is underrated. By keeping role approvals out of the API entirely, the attack surface for privilege escalation drops to zero from the network layer. An attacker with full API access still cannot elevate roles.
Authentication doesn't have to be a black box you rent from a vendor. By owning the entire stack — from Argon2id hashing to family-based token rotation to trigger-enforced audit immutability — you get a system that matches your exact security model, not someone else's lowest common denominator.
Build what you need. Own what you ship.